
发布时间:2025-11-12
在追求航空器设计极致性能与效率的今天,高性能计算(HPC)已成为推动多学科设计优化(MDO)发展的核心引擎。我国自主研发的新一代神威超级计算机,以超过10万个SW26010-Pro处理器节点、1.5 Exaflops峰值性能能力,为复杂工程系统的超大规模、高精度仿真与优化提供了前所未有的硬件平台。其澎湃算力,预示着在航空航天、船舶、能源等关键领域实现变革性突破的潜力。然而,将这种理论上的潜力转化为实际工程应用效能,面临着严峻的挑战。
新一代神威超算采用独特国产申威处理器、并实施严格“编译-执行”环境隔离(登录节点与计算节点架构异构、工具链隔离)的先进系统,对软件生态的适配性提出了极高的要求。当前主流开源MDO工具链(如基于PETSc、OpenMDAO等的框架)虽功能强大,但其开发与部署长期围绕国际主流x86生态进行,存在着显著的应用生态短板。这种不匹配直接导致了两个关键问题:
- 性能潜力难以释放: 工具链底层核心库(如PETSc、METIS、特定求解器等)缺乏对申威架构的原生优化和深度适配,无法充分利用“新一代神威超算”的异构计算优势和超大规模并行能力,计算效率远低于预期。
- 部署运行困难重重: 强制性的交叉编译环境、复杂的手动库依赖配置、自动化安装工具(pip, setup.py)在计算节点被禁用、以及对动态库兼容性的特殊要求等技术壁垒,使得在“新一代神威超算”上安装和调试庞大的开源MDO工具链变得极其复杂和脆弱,成为阻碍其实际应用的首要障碍。
本文将聚焦于以上核心挑战,简要阐述如何在新一代超算平台上成功安装、调试并运行一套完整的开源MDO工具链。
01 痛点:航空仿真的“卡脖子之锁”
1.1 新一代神威超算环境特点
1. 强制分离编译与执行
登录节点:唯一允许使用交叉编译器的环境,开发者需手动将C/C++扩展库编译为国产处理器适配的二进制文件(如.a静态库或指定路径的.so动态库)。
计算节点:仅支持运行预编译库,禁用pip install、setup.py等自动化编译安装工具,避免直接调用不兼容的本地编译器。
2. 库安装高度依赖手动操作
编译流程复杂:需人工指定交叉编译器路径(如SWGCC)、硬件指令集参数(-march=sw)、依赖库链接路径(-L/path/to/lib)等,配置错误将导致编译失败。
3. 异构环境隔离
登录节点与计算节点硬件架构不同(如神威处理器),编译器工具链严格隔离,强制交叉编译。
4. 定制化开发程度高
开发者需深度介入编译流程,手动指定CFLAGS、LDFLAGS等参数,适配目标环境。
1.2 两大痛点
硬件隔离:申威处理器与国际x86软件指令集不兼容
环境隔离:编译(登录节点)与运行(计算节点)严格分区,禁用自动化工具
1.3 “三无困境”
无适配:PETSc、Adflow等底层库缺乏动态库的移植经验
无协同:气动/结构/优化工具链断链
无验证:各模块无法进行大规模并行测试(缺少算例)、气动|结构耦合优化效率未知
02 MDO工具链介绍
2.1 MDO软件包整体介绍
密歇根大学的 MDO 实验室开发了具有高保真度 (MACH) 框架的飞机配置的 MDO。主要包含软件有:cgnsUtilities、baseclasses、pySpline、pyGeo、IDWarp、ADFlow、pyOptSparse、multipoint等。
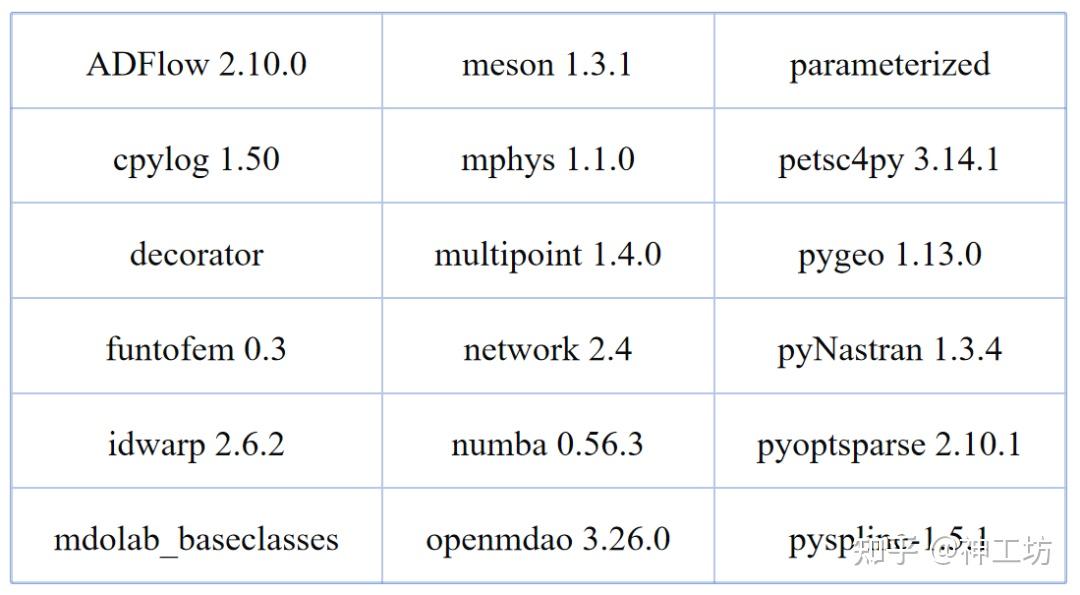
2.2 总结对比
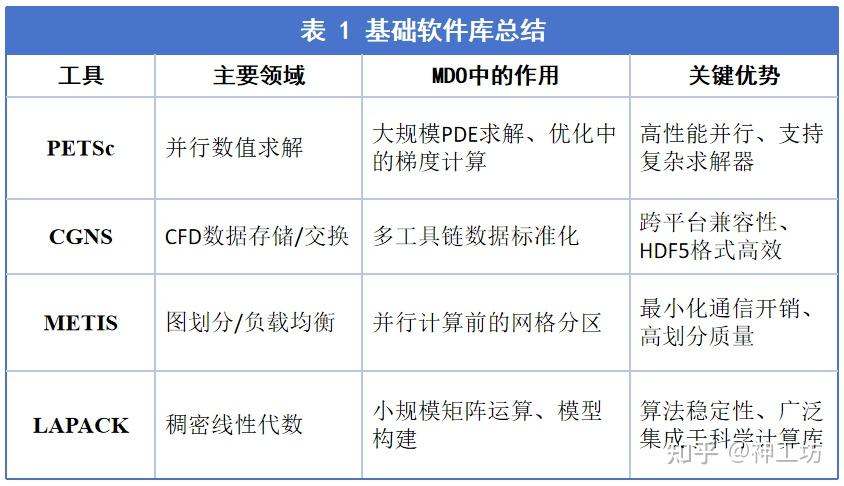
表 1 基础软件库总结
2.3 整体架构
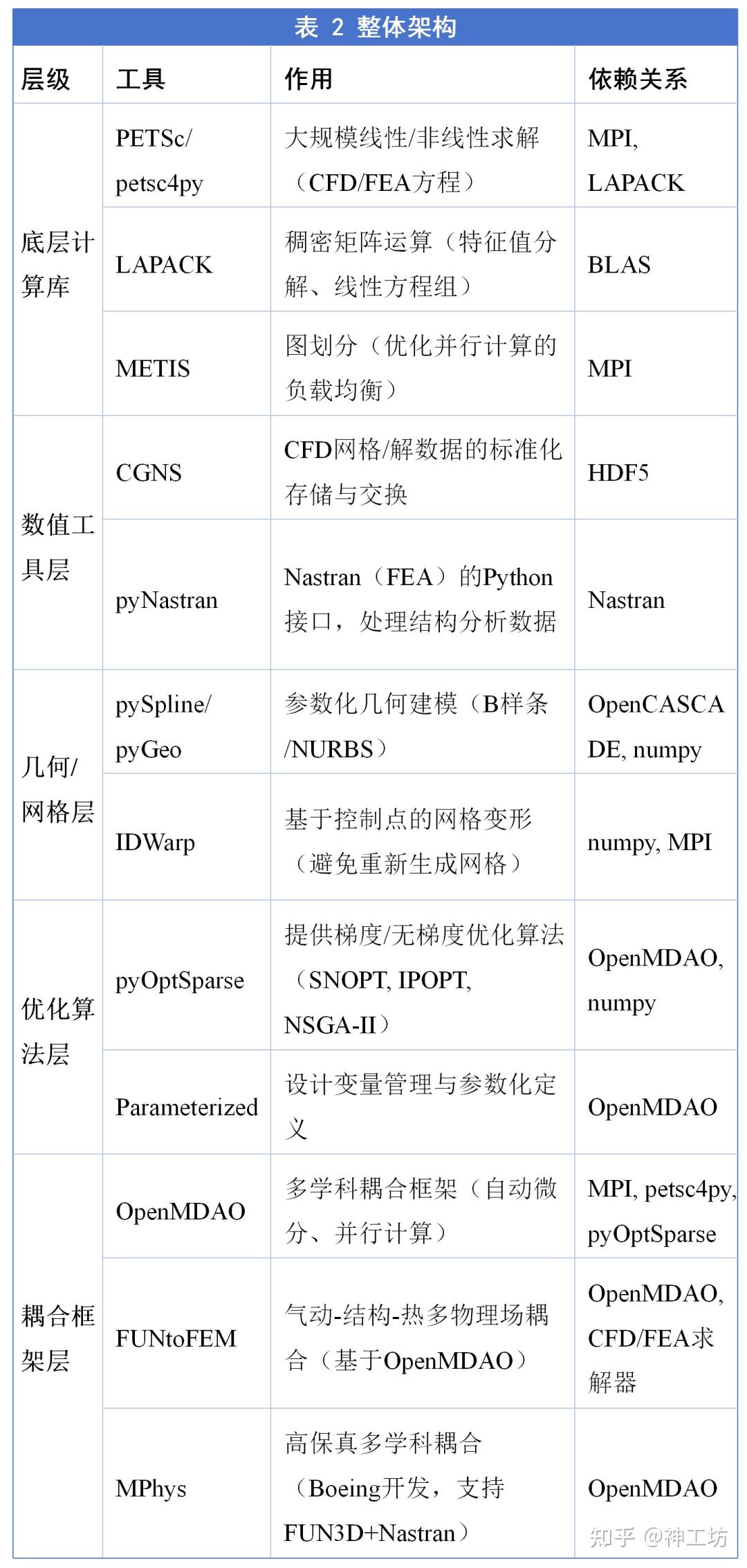
表 2 整体架构
03 破局:三大核心技术攻坚战
3.1 编译器“穿墙术”
1. Cmake安装方式
文件头部增加
set(CMAKE_SYSTEM_PROCESSOR sw_64)
set(CMAKE_C_COMPILER swgcc)
set(CMAKE_Fortran_COMPILER swgfortran)
2. configure+make安装方式
- petsc配置命令
./configure --with-shared-libraries=1 AR=swar RANLIB=swranlib --LD_SHARED=-mdynamic --LDFLAGS="-fPIC -mdynamic" CFLAGS="-fPIC -mieee" CXXFLAGS="-fPIC -mieee" FFLAGS="-fPIC -mieee" FCFLAGS="-fPIC -mieee" --with-scalar-type=real --with-mpi-dir=/usr/sw/mpi/mpi_current --with-batch=1 --download-fblaslapack=/home/export/online1/mdt00/shisuan/swgf_wx/chaos/dafoam/packages/petsc_lib/externalpackages/petsc-pkg-fblaslapack.tar.gz
3. Makefile方式
- TACS举例:
修改makefile.in
PYTHON = swpython
EXTRA_CC_FLAGS = -fPIC -O0 -g -mieee
SO_LINK_FLAGS=-fPIC -shared -mdynamic
LAPACK_LIBS = -L/~/lapack-3.10.1/build/lib -llapack -lpthread -lblas -lmpi
METIS_INCLUDE = -I${METIS_HOME}/include/ -I/usr/sw/mpi/mpi_current/include
4. python安装库时的编译问题
# 传统流程(崩溃)
pip install pyGeo # 在计算节点触发编译 → 失败!
# 神威方案(突围)
swgcc -mdynamic -fPIC *.c → 登录节点编译核心库
swpython setup.py install → 计算节点纯安装
3.2 动态库“复活术”
1. 目标
修复PETSc、Transform动态库引用时的nonzero padding致命错误。
2. 挑战
编译链接的库在神威平台无法识别。
3. 解决方案
成功安装后,会生成 petsc.so 动态库,但是该库如果直接使用会报错nonzero padding in e_ident。这是由于系统架构导致的,两种方法可以解决该问题。
- 方法1:将链接好的petsc.so下载到本地,使用软件winhex打开,将第9位数字2改为0,替换即可。
- 方法2:手动将编译好的文件进行链接
3.3 多节点“并行术”
超算平台的MPI函数实现不够全面,有些函数存在问题,例如MPI_Scatterv、MPI_Gatherv、MPI_Allreduce。如果逐个对程序的源码进行修改,存在耗时长、难定位、难测试等问题。比较好的解决办法是自己在底层mpi函数的基础上实现一套包含几个问题函数的动态库,在程序链接的时候把这个动态库加上。
以MPI_Allgatherv函数举例:
int MPI_Allgatherv(const void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *recvbuf, const int recvcounts[], const int displs[],
MPI_Datatype recvtype, MPI_Comm comm) {
int mpi_errno = MPI_SUCCESS;
int rank;
MPI_Comm_rank(comm, &rank);
if (sendbuf == MPI_IN_PLACE) {
MPI_Aint lb, extent;
mpi_errno = MPI_Type_get_extent(recvtype, &lb, &extent);
if (mpi_errno != MPI_SUCCESS) return mpi_errno;
// 获取当前进程的发送数据长度
int my_sendcount = recvcounts[rank];
MPI_Aint send_size = my_sendcount * extent;
// 创建临时发送缓冲区
void *tmp_sendbuf = malloc(send_size);
if (!tmp_sendbuf) return MPI_ERR_UNKNOWN;
// 从recvbuf的对应位置拷贝数据到临时缓冲区
char *src = (char *)recvbuf + displs[rank] * extent;
memcpy(tmp_sendbuf, src, send_size);
// 调用标准Allgatherv,发送类型和接收类型均为recvtype
mpi_errno = my_MPI_Allgatherv(tmp_sendbuf, my_sendcount, recvtype,
recvbuf, recvcounts, displs, recvtype, comm);
free(tmp_sendbuf);
} else {
// 正常调用标准Allgatherv
mpi_errno = my_MPI_Allgatherv(sendbuf, sendcount, sendtype,
recvbuf, recvcounts, displs, recvtype, comm);
}
return mpi_errno;
}
//其中my_MPI_Allgatherv函数是用MPI_Allgather实现的
04 测试成果
4.1 气动结构耦合优化算例并行测试
1. 算例参数
|
测试内容 |
ADFlow气动求解与TACS结构求解的并行测试 |
|
网格规模 |
21万 |
|
算例目标 |
重量与阻力系数 |
|
设计变量 |
攻角、机翼刨面翼型、扭转和结构厚度 |
|
约束 |
有机翼的厚度与体积不变、升力系数大于0.5 |
2. 测试目的
验证气动网格规模从3万增至21万时,流固耦合优化框架在多节点并行环境下的计算效率与稳定性。
软硬件环境:
- 硬件:新一代神威超算,超过十万核组。
- 软件:神威加速计算架构SACA
3. 测试结论
算例成功完成21万网格规模的流固耦合优化,验证了框架处理高分辨率模型的能力。多节点并行效率满足预期,气动/结构求解器协同稳定,为大规模工程优化提供可靠基础。
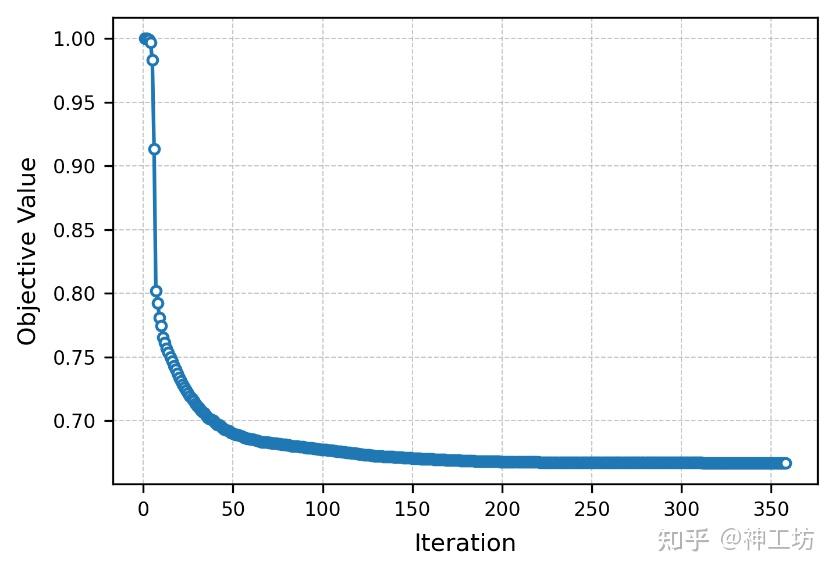
图 1 优化目标收敛曲线

图 2 压力云图

图 3 失效准则云图
4.2 气动结构耦合优化多工况并行测试
1. 算例描述
在前一个节气动结构耦合优化算例的基础上,增加工况数,保持优化目标,设计变量和约束不变。划分通信域,使得各个工况直接得以并行。
2. 测试目的
测试并行规模与并行效率,通过通过扩展工况数目,同时逐步增加核心数,直至总核心数超百万。
3. 测试结论
由测试结果可以看出,随着核心数的增加,并行效率出现了下降,百万核心相较于十万核心的并行效率为89.65%,符合预期。
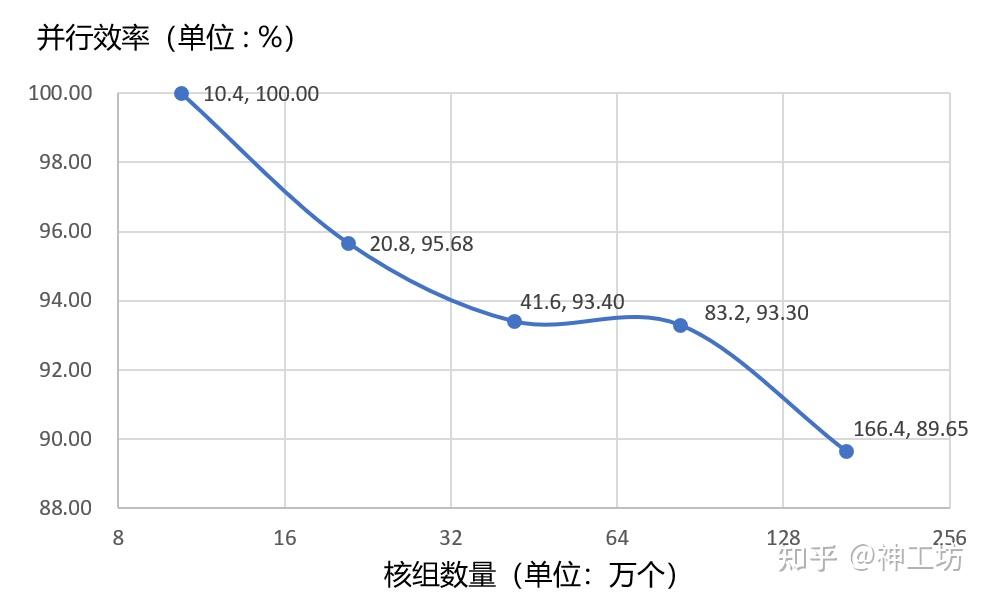
效率图 4 并行
05 结语
开源MDO工具链在新一代神威超算平台上的成功安装和调试,标志着国内首条完整适配国产申威处理器超算环境的开源MDO工具链实现了从“单点工具可用”到“全链路贯通”的重大突破。该成果不仅解决了航空仿真领域的“卡脖子”难题,还为国产处理器平台的软件生态建设提供了可行路径,具有显著的技术突破价值和深远的产业应用意义。




 神工坊知乎主页
神工坊知乎主页 皖公网安备34019202002742号
皖公网安备34019202002742号





